Es posible que desee leer este artículo primero: ¿Qué es la estimación de máxima verosimilitud ?
¿Qué es el Algoritmo EM?
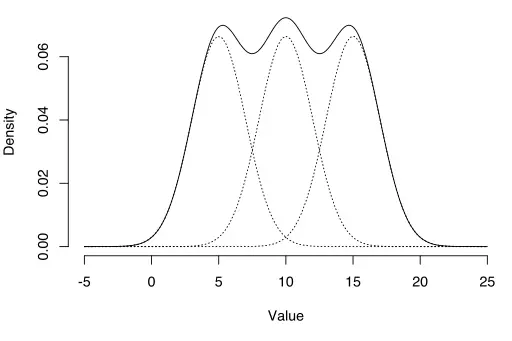
El algoritmo EM se puede usar para estimar variables latentes, como las que provienen de distribuciones mixtas (sabe que provienen de una mezcla, pero no de qué distribución específica).
El algoritmo Expectation-Maximization (EM) es una forma de encontrar estimaciones de máxima verosimilitud para los parámetros del modelo cuando sus datos están incompletos, faltan puntos de datos o tienen variables latentes no observadas (ocultas) . Es una forma iterativa de aproximar la función de máxima verosimilitud . Si bien la estimación de máxima verosimilitud puede encontrar el modelo de «mejor ajuste» para un conjunto de datos, no funciona particularmente bien para conjuntos de datos incompletos. El algoritmo EM más complejo puede encontrar parámetros del modelo incluso si faltan datos. Funciona eligiendo valores aleatorios para los puntos de datos faltantes y usando esas conjeturas para estimar un segundo conjunto de datos. Los nuevos valores se utilizan para crear una mejor suposición para el primer conjunto y el proceso continúa hasta que el algoritmo converge en un punto fijo.
Ver también: Algoritmo EM explicado en una imagen.
MLE frente a EM
Aunque la Estimación de Máxima Verosimilitud (MLE) y EM pueden encontrar parámetros de «mejor ajuste», la forma en que encuentran los modelos es muy diferente. MLE acumula todos los datos primero y luego usa esos datos para construir el modelo más probable. EM adivina los parámetros primero, teniendo en cuenta los datos faltantes, luego ajusta el modelo para que se ajuste a las conjeturas y los datos observados. Los pasos básicos para el algoritmo son:
- Se hace una estimación inicial de los parámetros del modelo y se crea una distribución de probabilidad . Esto a veces se llama el «E-Step» para el » distribución esperada”.
- Los datos recién observados se introducen en el modelo.
- La distribución de probabilidad del paso E se modifica para incluir los nuevos datos. Esto a veces se llama el «paso M».
- Los pasos 2 a 4 se repiten hasta que se alcanza la estabilidad (es decir, una distribución que no cambia del paso E al paso M).
El Algoritmo EM siempre mejora la estimación de un parámetro a través de este proceso de varios pasos. Sin embargo, a veces necesita algunos inicios aleatorios para encontrar el mejor modelo porque el algoritmo puede perfeccionar un máximo local que no está tan cerca del máximo global (óptimo) . En otras palabras, puede funcionar mejor si lo fuerza a reiniciarse y toma esa «suposición inicial» del Paso 1 nuevamente. De todos los parámetros posibles, puede elegir el que tenga la mayor probabilidad máxima.
En realidad, los pasos involucran algunos cálculos bastante pesados ( integración ) y probabilidades condicionales , que están más allá del alcance de este artículo. Si necesita un desglose más técnico (es decir, basado en cálculos) del proceso, le recomiendo que lea el artículo de Gupta y Chen de 2010.
Aplicaciones
El algoritmo EM tiene muchas aplicaciones, que incluyen:
- Desenmarañar señales superpuestas,
- Estimación de modelos de mezcla gaussiana (GMM),
- Estimación de modelos ocultos de Markov (HMM),
- Estimación de parámetros para distribuciones de Dirichlet compuestas ,
- Encontrar mezclas óptimas de modelos fijos.
Limitaciones
El algoritmo EM puede ser muy lento , incluso en la computadora más rápida. Funciona mejor cuando solo tiene un pequeño porcentaje de datos faltantes y la dimensionalidad de los datos no es demasiado grande. Cuanto mayor sea la dimensionalidad, más lento será el paso E; para datos con mayor dimensionalidad, es posible que el paso E se ejecute extremadamente lento a medida que el procedimiento se acerca a un máximo local.
Referencias :
Dempster, A., Laird, N. y Rubin, D. (1977) Máxima probabilidad de datos incompletos a través del algoritmo EM, Journal of the Royal Statistical Society. Serie B (Metodológica), vol. 39, núm. 1, págs. 1-38.
Gupta, M. & Chen, Y. (2010) Teoría y Uso del Algoritmo EM. Fundamentos y tendencias en el procesamiento de señales, vol. 4, núm. 3, 223–296.