Contenido de este artículo
- 0
- 0
- 0
- 0
Actualizado el 9 de febrero de 2022, por Luis Benites.
¿Qué es la validación cruzada?
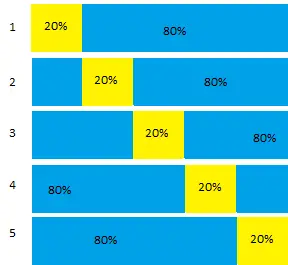
En la validación cruzada quíntuple, se entrena el 80% de los datos; Se prueba el 20%. el proceso se ejecuta 5 veces para cubrir todos los datos.
La validación cruzada (también llamada estimación de rotación o prueba fuera de la muestra ) es una forma de garantizar que su modelo sea sólido . Se retiene una parte de sus datos (llamada muestra reservada); La mayor parte de los datos se entrenan y la muestra reservada se usa para probar el modelo. Esto es diferente del método «clásico» de prueba de modelos, que utiliza todos los datos para probar el modelo.
La validación cruzada no prevaleció hasta que surgieron grandes conjuntos de datos. Antes de eso, los analistas preferían usar todos los datos disponibles para probar un modelo. Con conjuntos de datos más grandes, tiene sentido retener una parte de los datos para probar el modelo. Sin embargo, la pregunta es qué parte de los datos retiene. La mayoría de los datos no son homogéneos en toda su longitud, por lo que si elige el fragmento de datos incorrecto, podría invalidar un modelo perfectamente bueno. La validación cruzada resuelve este problema mediante el uso de múltiples muestras secuenciales reservadas que cubren todos los datos.
Ejemplo de plegado en K
En la validación cruzada K-fold (a veces llamada v fold, para «v» partes iguales), los datos se dividen en k subconjuntos aleatorios. Se ajustan un total de k modelos y se obtienen k estadísticos de validación.
Digamos que desea ejecutar un algoritmo básico de 5 veces, como el que se muestra en la imagen de arriba. El procedimiento básico es:
- Establecer 1/K = 1/5 (20%) de los datos aparte (elegidos al azar).
- Entrene el 80% restante de los datos.
- Califique el modelo en función de la muestra reservada y registre las métricas necesarias del modelo.
- Restaure la muestra reservada y luego repita, anotando el próximo 20% de los datos.
- Repita el procedimiento hasta que todos los datos hayan sido incluidos en una muestra reservada.
- Encuentre la media (o similar) de las métricas del modelo.
La validación cruzada de exclusión es K-fold con K = N, el número de puntos de datos en el conjunto.
Validación cruzada de Monte Carlo
Monte Carlo CV trabaja con la misma idea que K-Fold, donde un porcentaje de datos forma el conjunto de entrenamiento; el resto de datos es el conjunto de prueba. La principal diferencia es que con K-fold, todos los datos se usan exactamente una vez. Con Monte Carlo, cada muestra reservada se elige de forma independiente. Por ejemplo, supongamos que su conjunto de datos se compone de 25 puntos, AY.
5-Fold dividiría los datos en:
- {A B C D E},
- {FGHIJ},
- {KLMNO},
- {PQRST},
- {UVWXY}.
Monte Carlo elegiría 5 puntos al azar, quizás {ACWXY}. Esos elementos se vuelven a colocar en el conjunto y luego se eligen 5 puntos al azar, con reemplazo, quizás {ABKPR}. El elemento «A» se ha elegido dos veces en este ejemplo, lo cual está permitido en Monte Carlo.
Ventajas y desventajas
La validación cruzada se puede utilizar en conjuntos de datos que van desde pequeños a grandes. Con conjuntos de datos más pequeños, la validación cruzada k-fold hace un uso eficiente de los datos limitados (SAS, 2017). La validación cruzada es particularmente útil para modelos complejos. Por ejemplo, podría usarse en modelos con procesos iterativos que respondan a estructuras de datos locales (Bruce & Bruce, 2017). La desventaja es que el método es computacionalmente costoso.
Referencias
Bruce, P. y Bruce A. (2017). Estadísticas prácticas para científicos de datos: 50 conceptos esenciales. Recuperado el 25 de mayo de 2019 de: https://books.google.com/books?id=ldPTDgAAQBAJ
Dangeti, P. (2017). Estadísticas para Machine Learning . Packt Publishing Ltd. Recuperado el 25 de mayo de 2019 de: https://books.google.com/books?id=C-dDDwAAQBAJ.
SAS (2017). JMP 13 Ajuste de modelos lineales, segunda edición.
Redactor del artículo
¿Te hemos ayudado?
Ayudanos ahora tú, dejanos un comentario de agradecimiento, nos ayuda a motivarnos y si te es viable puedes hacer una donación:La ayuda no cuesta nada
Por otro lado te rogamos que compartas nuestro sitio con tus amigos, compañeros de clase y colegas, la educación de calidad y gratuita debe ser difundida, recuerdalo:
