La imputación múltiple (IM) es una forma de lidiar con el sesgo de falta de respuesta : datos de investigación faltantes que ocurren cuando las personas no responden a una encuesta. La técnica le permite analizar datos incompletos con herramientas regulares de análisis de datos como una prueba t o ANOVA . Imputar significa «completar». Con los métodos de imputación singular, se utiliza la media , la mediana o alguna otra estadística para imputar los valores faltantes. Sin embargo, el uso de valores únicos conlleva un nivel de incertidumbre sobre qué valores imputar. La imputación múltiple reduce la incertidumbre sobre los valores faltantes mediante el cálculo de varias opciones diferentes («imputaciones»). Se crean varias versiones del mismo conjunto de datos, que luego se combinan para obtener los «mejores» valores.
Ventajas de la imputación múltiple
Utilizado correctamente, MI puede:
- Reducir el sesgo . “Sesgo” se refiere a errores que se deslizan en su análisis.
- Mejorar la validez . La validez simplemente significa que una prueba o instrumento mide con precisión lo que se supone que debe hacer. Por ejemplo, cuando crea una prueba o cuestionario para la depresión, desea que las preguntas midan realmente la depresión y no otra cosa (como la ansiedad).
- Aumente la precisión . La precisión es lo cerca que están dos o más medidas entre sí.
- Da como resultado estadísticas sólidas , que son resistentes a los valores atípicos (puntos de datos muy altos o muy bajos).
Cálculo de imputaciones
Con el método de imputaciones múltiples, los valores faltantes se reemplazan por m > 1 posibilidades, donde m suele ser < 10.
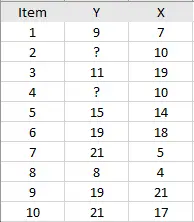
A esta tabla le faltan valores de datos para Y2 y Y4.
El procedimiento general, muy simplificado (como lo describe Rubin, 1987) es una serie de pasos:
- Ajuste sus datos a un modelo apropiado . El ajuste del modelo toma datos de muestras e intenta encontrar el modelo que mejor se ajuste, como una distribución normal o una distribución de chi-cuadrado . El modelo también podría ser algún otro modelo paramétrico extraído de sus datos. Para la tabla anterior, se crearon dos modelos simples (con dos imputaciones): el vecino más cercano , que tomó los valores del vecino de arriba y el vecino de abajo y el vecino más cercano + 25 %, que incrementó los valores del vecino más cercano para tener en cuenta el sesgo de falta de respuesta .
- Estime un punto de datos que falta utilizando el modelo seleccionado. Por ejemplo, el modelo vecino más cercano podría generar un 9 para el valor faltante Y2. 9 es el valor encontrado en uno de los vecinos más cercanos (Y1).
- Repita los pasos 1 y 2 (puede usar el mismo modelo o modelos diferentes) de 2 a 5 veces para cada punto de datos faltantes (esto le brinda múltiples opciones para los datos faltantes).
- Realice su análisis de datos . Por ejemplo, es posible que desee ejecutar una prueba t o un ANOVA . La prueba debe ejecutarse en todos los conjuntos de puntos de datos faltantes. Este ejemplo generó los cuatro conjuntos a continuación, por lo que las pruebas elegidas se ejecutarán cuatro veces (una para cada conjunto).
- Promedie los valores de las estimaciones de los parámetros , las varianzas o los errores estándar obtenidos de cada modelo para dar una estimación puntual única para ese modelo. En otras palabras, puede combinar los resultados de los dos conjuntos de datos generados a partir del modelo 1 y también puede combinar los resultados de los dos conjuntos de datos generados a partir del modelo 2.
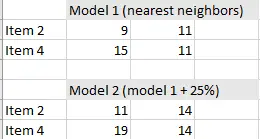
Imputaciones para los puntos de datos faltantes calculados a partir de los dos modelos (redondeados al número entero más cercano ).
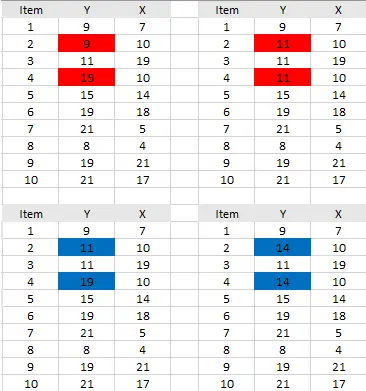
Aunque el ejemplo simplificado anterior puede parecer intuitivo, los cálculos para aproximar los valores perdidos son sorprendentemente complejos . Implican:
- Análisis bayesiano , que combina información previa sobre un parámetro de interés con nueva evidencia de una muestra.
- Remuestreo de distribuciones predichas, donde se extraen repetidamente grandes cantidades de muestras más pequeñas del mismo tamaño, con reemplazo, de una sola muestra original.
No solo se calculan múltiples posibilidades para los valores faltantes, sino que cada valor sugerido puede provenir de una distribución de probabilidad diferente . Este análisis es prácticamente imposible a mano sin una buena comprensión de la metodología bayesiana. Schafer (1999) advierte que
“…un método de imputación ingenuo o sin principios puede crear más problemas de los que resuelve, distorsionando estimaciones, errores estándar y pruebas de hipótesis”.
Para evitar estas trampas, Rubin (1991) recomienda que las imputaciones deberían:
- Aplique una distribución de probabilidad previa a cualquier parámetro desconocido utilizando el análisis bayesiano, simulando m sorteos independientes de la distribución condicional de Y faltante dada Y observada por el teorema de Bayes ,
- Especifique un modelo paramétrico para los datos completos,
- Especifique (si es posible) un modelo para el mecanismo subyacente que causa la falta de datos.
Uso de software
Los paquetes de software estadístico más populares tienen opciones para la imputación múltiple, que requieren poca comprensión del funcionamiento bayesiano de fondo. Por ejemplo, el procedimiento MI de IBM SPSS es básicamente apuntar y hacer clic:
- Elija Analizar > Imputación múltiple.
- Seleccione >2 variables para el modelo.
- Especifique el número de imputaciones. El valor predeterminado es 5.
- Especifique el conjunto de datos o el archivo de datos para su salida.
Otras opciones populares de software incluyen:
- R: Analytics Vidhya tiene un buen resumen de varios paquetes R que se ocupan de los datos faltantes, incluidas las imputaciones múltiples.
- SAS : Utilice los procedimientos PROC MI o PROC MIANALYZE.
El uso de software no es una solución perfecta. Se debe tener cuidado para elegir modelos apropiados para sus datos. Por ejemplo, si sus datos no se distribuyen normalmente, es posible que deba transformar sus variables para que se aproximen a una distribución normal antes de ejecutar un procedimiento de imputación. En otras palabras, no es tan simple como ingresar sus datos y hacer clic en una opción de imputación múltiple. Las elecciones de modelo incorrectas, la falta de inclusión de variables moderadoras o la exclusión de puntos de datos vitales pueden conducir a un sesgo aún mayor del que habría tenido sin ejecutar el procedimiento en primer lugar.
Otras opciones para datos faltantes

Existen muchas opciones para completar los datos faltantes.
No existe un método «perfecto» para completar los datos que faltan. Como se describió anteriormente, las imputaciones múltiples pueden ser difíciles de entender e implementar sin una cierta comprensión de la selección del modelo y la teoría bayesiana. Algunas otras opciones, que son más simples y pueden ser más eficientes que MI, incluyen:
- Reemplace los valores faltantes con la media o la mediana del conjunto. Por lo general, no se recomienda a menos que solo tenga algunos valores faltantes.
- Utilice la regresión lineal para completar los espacios en blanco. La regresión lineal crea un modelo simple (una línea) donde es fácil extrapolar o interpolar valores faltantes. Solo es adecuado para datos que probablemente sean lineales, como la altura, el peso o los niveles de ingresos.
- Reemplace los valores faltantes con el valor anterior . Esto puede funcionar si sus valores parecen tener una tendencia (a diferencia de los valores que están por todas partes).
- Ignore los casos con datos faltantes o pondere los casos completos (es decir, dé más importancia a los datos completos y menos importancia a los datos incompletos). Ignorar los casos con datos faltantes puede ser una opción si tiene un tamaño de muestra lo suficientemente grande . Para muestras más pequeñas, cada punto de datos puede ser crítico.
- Rellene los espacios en blanco con ceros . Principalmente una opción si tiene algunos puntos faltantes no críticos.
- Utilice un algoritmo EM o vecino más cercano para generar puntos de datos faltantes. La coincidencia del vecino más cercano hace coincidir lógicamente un punto de datos con otro punto de datos más similar. El algoritmo EM funciona eligiendo valores aleatorios para los puntos de datos faltantes y usando esas conjeturas para estimar un segundo conjunto de datos. Los nuevos valores se utilizan para crear una mejor suposición para el primer conjunto y el proceso continúa hasta que el algoritmo converge en un punto fijo.
Lectura adicional:
Para una mirada en profundidad a la MI, realmente no se puede superar el trabajo original de DB Rubin Imputación múltiple para la falta de respuesta en las encuestas (Nueva York: John Wiley, 1987). Si no puede encontrar el libro, puede leer un pdf del método MI de Rubin aquí .
Referencias:
Little RJA & Rubin DB (2002) Análisis estadístico con datos faltantes (segunda edición) . Wiley, Nueva Jersey.
Rubín , DB (1977). Inferencia y datos perdidos. Biometrika, 63, 581-592.
Rubín , DB (1978). Imputaciones múltiples en encuestas por muestreo: un enfoque bayesiano fenomenológico de la falta de respuesta. Procedimientos de la sección de métodos de investigación de encuestas de la Asociación Estadounidense de Estadística, 20-34. También en imputación y edición de datos de encuestas defectuosos o faltantes, Departamento de Comercio de EE. UU., 1-23.
Rubín, DB (1986). Ideas básicas de imputación múltiple por falta de respuesta. Metodología de la encuesta, junio de 1986. Vol 12, No.1, pp. 37-47. Recuperado el 24/8/2017 de: http://www.statcan.gc.ca/pub/12-001-x/1986001/article/14439-eng.pdf
Schafer , J. (1999). Imputación múltiple: una cartilla. Recuperado el 23/8/2017 de: http://hbanaszak.mjr.uw.edu.pl/TempTxt/Schafer_1999_MultipleImputationAPrimer.pdf