Contenido de este artículo
- 0
- 0
- 0
- 0
Actualizado el 30 de mayo de 2022, por Luis Benites.
Una distribución previa representa su creencia sobre el verdadero valor de un parámetro . Es su «mejor suposición». Una vez que haya realizado algunas observaciones, vuelva a calcular con nueva evidencia para obtener la distribución posterior .
Formalmente, la nueva evidencia se resume con una función de verosimilitud , por lo que:
¿Cómo creo una distribución previa?
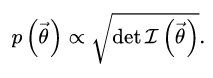
El anterior de Jeffrey es una opción poco informativa.
Podría simplemente tomar su mejor suposición y dibujar algún tipo de distribución de probabilidad (con algunos parámetros descriptivos como la media o la desviación estándar ).
Si no tiene ni idea de cómo debería verse la distribución, entonces use lo que se llama un previo no informativo (o Prior de Jeffrey ). Es exactamente lo que parece y es equivalente a sacar una distribución de un sombrero. Incluso si su modelo es completamente irrazonable, una vez que haya realizado algunas observaciones, su distribución posterior será una mejora con respecto a su suposición inicial. De hecho, una distribución no informativa tiene muy poco efecto sobre una distribución posterior, en comparación con una distribución anterior conocida.
Más formalmente, esas conjeturas sobre los parámetros se denominan hiperparámetros , parámetros estimados que no involucran datos observados. Los hiperparámetros capturan sus creencias previas, antes de que se observen los datos (Riggelsen, 2008).
Calcular una distribución previa es la parte fácil. El escollo es convertir esa distribución anterior en una distribución posterior. Incorporar creencias previas en una distribución de probabilidad no es tan fácil como parece. Una opción es el algoritmo Metropolis-Hastings , que puede crear una aproximación para una distribución posterior (es decir, crear un histograma ) a partir de la distribución anterior y cualquier muestra observada .
Referencias
Riggelsen, C. (2008). Métodos de Aproximación para el Aprendizaje Eficiente de Redes Bayesianas . Prensa IOS.
Redactor del artículo
¿Te hemos ayudado?
Ayudanos ahora tú, dejanos un comentario de agradecimiento, nos ayuda a motivarnos y si te es viable puedes hacer una donación:La ayuda no cuesta nada
Por otro lado te rogamos que compartas nuestro sitio con tus amigos, compañeros de clase y colegas, la educación de calidad y gratuita debe ser difundida, recuerdalo:
