Contenido de este artículo
- 1 ¿Qué es la tasa de descubrimiento falso?
- 2 Fórmula FDR
- 3 Tasas de falso descubrimiento en la prueba de hipótesis
- 4 Tasas de descubrimiento falso en pruebas médicas
- 5 Ajuste de la tasa de descubrimiento falso
- 6 Cuándo no corregir
- 7 Ejemplo de caso: la tasa de descubrimiento falso
- 8 Referencias
- 9 Redactor del artículo
- 10 ¿Te hemos ayudado?
- 0
- 0
- 0
- 0
Actualizado el 26 de marzo de 2022, por Luis Benites.
¿Qué es la tasa de descubrimiento falso?
La tasa de descubrimiento falso (FDR) es la proporción esperada de errores de tipo I. Un error tipo I es cuando rechaza incorrectamente la hipótesis nula ; En otras palabras, obtienes un falso positivo .
Estrechamente relacionado con el FDR está la tasa de error familiar (FWER) . El FWER es la probabilidad de hacer al menos una conclusión falsa (es decir, al menos un error de tipo I). En otras palabras, es la probabilidad de cometer cualquier error Tipo I. La corrección de Bonferroni controla el FWER, evitando que se produzcan uno o más falsos positivos. Sin embargo, el uso de esta corrección puede ser demasiado estricto para algunos campos y puede dar lugar a resultados perdidos (Mailman School of Public Health, nd). El enfoque FDR se utiliza como una alternativa a la corrección de Bonferroni y controla una baja proporción de falsos positivos, en lugar de evitar hacer cualquier conclusión positiva falsa en absoluto. El resultado suele ser un mayor poder estadístico y menos errores de tipo I.
Fórmula FDR
La fórmula de la tasa de descubrimiento falso (Akey, nd) es:
FDR = E(V/R | R > 0) P(R > 0)
Donde:
- V = Número de errores de tipo I (es decir, falsos positivos)
- R = Número de hipótesis rechazadas
En una forma más básica, la fórmula simplemente dice que el FDR es el número de falsos positivos en todas las hipótesis rechazadas. La información después de | El símbolo («dado») simplemente indica que:
- Tiene al menos una hipótesis rechazada,
- La probabilidad de obtener al menos una hipótesis rechazada es mayor que cero.
Tasas de falso descubrimiento en la prueba de hipótesis
Según David Colquhoun de la Universidad de Londres, “ Es bien sabido que se producen altas tasas de falsos descubrimientos cuando se prueban muchos resultados de una única intervención. “Gracias al poder de la informática, ahora podemos probar una hipótesis millones de veces, lo que puede dar como resultado cientos de miles de falsos positivos.
Para una mirada más humorística (quizás comprensible) a los problemas de la prueba repetida de hipótesis y las altas tasas de descubrimiento falso, eche un vistazo al «Problema Jelly Bean» de XKCD. El cómic muestra a un científico que encuentra un vínculo entre el acné y las gominolas, cuando se probó una hipótesis con un nivel de significación del 5 % . Aunque no existe una relación entre las gominolas y el acné, se encontró un resultado significativo (en este caso, una gominola causó acné) al realizar pruebas varias veces. Probando 20 colores de gominolas, el 5% de las veces hay 1 gominola que se señala incorrectamente como el culpable del acné. Las implicaciones para el descubrimiento falso en la prueba de hipótesis es que si repite una prueba suficientes veces, encontrará un efecto… pero es posible que ese efecto en realidad no exista.
La probabilidad de que obtenga un resultado falso positivo cuando realiza solo 20 pruebas es de un 64,2 %. Esta cifra se obtiene calculando primero las probabilidades de no tener descubrimientos falsos a un nivel de significación del 5 % para 20 pruebas:
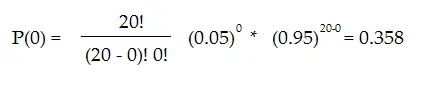
La probabilidad de 20 intentos no tendrá conclusiones falsas (usando la fórmula binomial ).
Si la probabilidad de no tener conclusiones falsas es del 35,8%, entonces la probabilidad de una conclusión falsa (es decir, una gominola verde que causa acné) es del 64,2%.
Volver arriba
Tasas de descubrimiento falso en pruebas médicas
En las pruebas médicas, la tasa de descubrimiento falso es cuando obtiene un resultado «positivo» pero en realidad no tiene la enfermedad. Es el complemento del valor predictivo positivo (PPV) , que le indica la probabilidad de que un resultado positivo de la prueba sea exacto. Por ejemplo, si el PPV fuera del 60 %, la tasa de descubrimiento falso sería del 40 %. La imagen a continuación muestra una prueba médica que identifica con precisión el 90% de las enfermedades/casos reales. La tasa de descubrimiento falso es la relación entre el número de falsos positivos resultados al número total de resultados positivos de la prueba. De 10,000 personas a las que se les hizo la prueba, hay 450 resultados positivos verdaderos (cuadro en la parte superior derecha) y 190 resultados falsos positivos (cuadro en la parte inferior derecha) para un total de 640 resultados positivos. De estos resultados, 190/640 son falsos positivos, por lo que la tasa de descubrimiento falso es del 30 %.

Ajuste de la tasa de descubrimiento falso
Si repite una prueba las suficientes veces, siempre obtendrá una cantidad de falsos positivos. Uno de los objetivos de las pruebas múltiples es controlar el FDR: la proporción de estos resultados erróneos. Por ejemplo, puede decidir que una tasa FDR de más del 5 % es inaceptable. Tenga en cuenta, sin embargo, que aunque el 5% suena razonable, si está haciendo muchas pruebas (especialmente comunes en la investigación médica), también obtendrá una gran cantidad de falsos positivos; para 1000 pruebas, podría esperar obtener 50 falsos positivos solo por casualidad. Esto se conoce como el problema de las pruebas múltiples , y el enfoque FDR es una forma de controlar el número de falsos positivos .
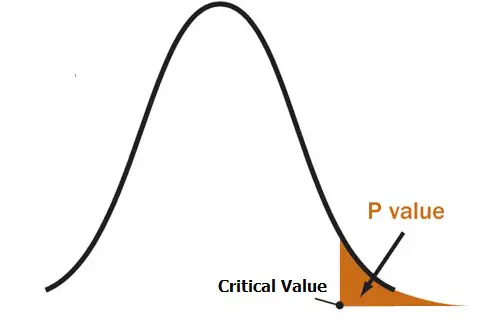
Un valor p es un área en la cola de una distribución que le indica las probabilidades de que un resultado ocurra por casualidad.
El enfoque FDR ajusta el valor p para una serie de pruebas. Un valor p le da la probabilidad de un falso positivo en una sola prueba; Si está ejecutando una gran cantidad de pruebas a partir de muestras pequeñas (que son comunes en campos como la genómica y la protoémica), debe usar valores q en su lugar.
- Un valor p del 5 % significa que el 5 % de todas las pruebas darán falsos positivos.
- Un valor q del 5 % significa que el 5 % de los resultados significativos serán falsos positivos.
El procedimiento para controlar el FDR, utilizando valores q, se denomina procedimiento de Benjamini-Hochberg , llamado así por Benjamini y Hochberg (1995), quienes lo describieron por primera vez.
Cuándo no corregir
Aunque controlar los errores de tipo I suena ideal (¿por qué no establecer el umbral realmente bajo y terminar con eso?), los errores de tipo I y tipo II forman una relación inversa; cuando uno baja, el otro sube y viceversa. Al disminuir los falsos positivos , aumenta la cantidad de falsos negativos; ahí es donde hay un efecto real, pero fallas en detectarlo. En muchos casos, un aumento de falsos negativos puede no ser un problema. Pero si los falsos negativos son costosos o de vital importancia para futuras investigaciones, es posible que no desee corregir los falsos positivos en absoluto (McDonald, 2014). Por ejemplo, supongamos que está investigando una nueva vacuna contra el SIDA. Una gran cantidad de falsos positivos puede ser un indicio de que está en el camino correcto y puede indicar potencial para futuras investigaciones sobre la vacuna. Pero si corrige en exceso, puede perder esas posibilidades.
Volver arriba
Ejemplo de caso: la tasa de descubrimiento falso
Matemáticamente, la probabilidad de error de tipo I se denota con la letra griega alfa minúscula, α. El nivel de porcentaje de confianza es (1 – α) * 100%. Entonces, un nivel alfa de 0.05 es equivalente a un nivel de confianza del 95%. La probabilidad de error de tipo II se denota con la letra griega minúscula beta, β. La potencia es 1 – β (no convertida en porcentaje). Así, por ejemplo, un nivel beta de 0,20 equivale a un nivel de potencia de 0,80.
Imagine que hay 1000 hipótesis para probar y que 100 de las hipótesis nulas son realmente falsas y 900 de las hipótesis nulas son realmente verdaderas. Supongamos que se trata de 1000 estudios separados para determinar si ciertos alimentos y suplementos dietéticos afectan la salud de las personas, por lo que cada hipótesis nula establece que un determinado alimento o suplemento dietético no tiene ningún efecto sobre la salud. Suponga que se utiliza un nivel alfa de 0,05 ( 95 % de confianza ). Suponga también que la probabilidad de error tipo II, beta, es 0,20 y, por lo tanto, el poder estadístico es 0,80. Estos son niveles bastante realistas, aunque una potencia de 0,80 es probablemente más alta (mejor) de lo que muchos estudios tendrían.
Con una probabilidad alfa de 0,05 para el error de tipo I, espere 900 * 0,05 = 45 errores de tipo I y espere 900 * 0,95 = 855 no rechazos correctos de la hipótesis nula. Con una probabilidad beta de 0,20 para el error de tipo II, espere 100 * 0,20 = 20 errores de tipo II y espere 100 * 0,80 = 80 rechazos correctos de la hipótesis nula. Por lo tanto, esperamos un total de 45 + 80 = 125 Hipótesis Nulas rechazadas .
¿Qué porcentaje de las Hipótesis Nulas rechazadas esperamos que sean erróneamente rechazadas? Esta es nuestra tasa de descubrimiento falso. Según lo anterior, esperamos que 45 se rechacen por error y esperamos que 80 se rechacen correctamente. Por lo tanto, esperamos que 45/(45 + 80) = 36% de las Hipótesis Nulas rechazadas sean erróneamente rechazadas. Dado que las hipótesis nulas rechazadas tienden a obtener toda la publicidad, debería encontrar esto revelador. (Los titulares de hipótesis nulas rechazadas pueden ser afirmaciones como «¡Este suplemento mejora significativamente la salud!» y «¡Este alimento es un riesgo significativo para la salud!»)
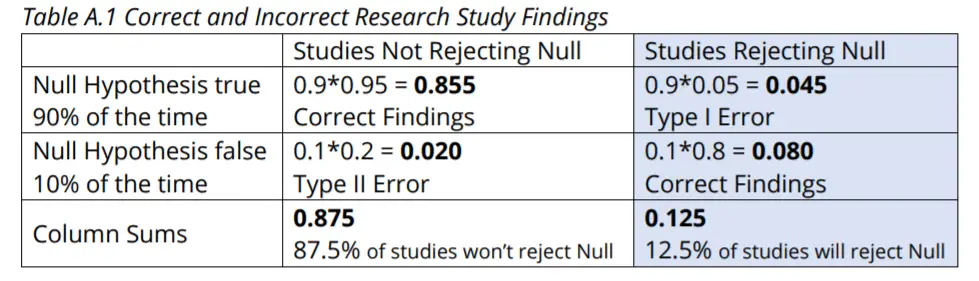
También podemos exponer esto en una Tabla (A.1) de probabilidades. Usando la columna más a la derecha para calcular la proporción de estudios que rechazan la Hipótesis Nula que son Errores Tipo I nos da 0.045 / 0.125 = 0.360 = 36%. El 36% se puede mejorar aumentando los tamaños de muestra en los 1000 estudios. Esto aumentará la potencia. Si aumentamos la potencia a 0,9, por ejemplo, aumentaremos los rechazos correctos de 80 a 90. Idealmente, si podemos aumentar el tamaño de la muestra lo suficiente, podemos establecer nuestro alfa en 0,01, disminuyendo así el 45 a 9, mientras que también manteniendo o incluso aumentando el poder. Con alfa de 0,01, beta de 0,10 y, por lo tanto, potencia de 0,90, reduciríamos la tasa de descubrimiento falso a 9 / (9 + 90) = 9 %. Esto es mucho mejor, pero también es mucho más caro reunir los
grandes cantidades de datos adicionales que se requieren.
Por último, tenga en cuenta que la tasa de descubrimiento falso del 36% que obtuvimos depende de nuestra suposición de que solo 100 de las 1000 hipótesis nulas son realmente falsas. Si los investigadores tienen buenas teorías para guiar su elección de hipótesis, entonces la proporción de hipótesis nulas que son verdaderamente falsas debería ser mayor y la tasa de descubrimiento falso debería ser menor.
Referencias
:
Akey, J. (sf). Lección 10: Pruebas Múltiples. Artículo publicado en el sitio web de la Universidad de Washington. Recuperado el 29 de octubre de 2017 de: http://www.gs.washington.edu/academics/courses/akey/56008/lecture/lecture10.pdf.
Benjamini, Y. y Hochberg, Y. (1995). Controlando la Tasa de Descubrimiento Falso: Un Enfoque Práctico y Poderoso para las Pruebas Múltiples. Revista de la Real Sociedad Estadística. Serie B (Metodológica) Vol. 57, No. 1, pp. 289-300
Colquhoun, D. Una investigación de la tasa de descubrimiento falso y la mala interpretación de los valores de p. Publicado el 19 de noviembre de 2014. Disponible aquí .
Escuela de Salud Pública Mailman (nd). Artículo publicado en el sitio web de la Universidad de Columbia. Recuperado el 29/10/2017 de: https://www.mailman.columbia.edu/research/population-health-methods/false-discovery-rate
“Jelly Bean Problem” de XKCD.
McDonald, JH 2014. Manual de estadísticas biológicas (3.ª ed.). Editorial Sparky House, Baltimore, Maryland. Recuperado el 29 de octubre de 2017 de: http://www.biostathandbook.com/multiplecomparisons.html
Redactor del artículo
¿Te hemos ayudado?
Ayudanos ahora tú, dejanos un comentario de agradecimiento, nos ayuda a motivarnos y si te es viable puedes hacer una donación:La ayuda no cuesta nada
Por otro lado te rogamos que compartas nuestro sitio con tus amigos, compañeros de clase y colegas, la educación de calidad y gratuita debe ser difundida, recuerdalo:
