Contenido de este artículo
- 0
- 0
- 0
- 0
Actualizado el 3 de mayo de 2022, por Luis Benites.
Es posible que desee leer este artículo primero: ¿Qué es el error estándar de una muestra?
¿Qué son los errores estándar agrupados?
Los errores estándar agrupados (CSE) ocurren cuando algunas observaciones en un conjunto de datos están relacionadas entre sí . Esta correlación ocurre cuando un rasgo individual, como la habilidad o el nivel socioeconómico, es idéntico o similar para grupos de observaciones dentro de conglomerados. Los datos de panel (datos multidimensionales recopilados a lo largo del tiempo) suelen ser el tipo de datos asociados con los CSE.
Por ejemplo, supongamos que desea saber si el tamaño de la clase afecta los puntajes del SAT . Específicamente, usted piensa que el tamaño más pequeño de la clase conduce a mejores puntajes en el SAT. Recopila datos de panel para docenas de clases en docenas de escuelas. Como se trata de datos de panel, es casi seguro que tiene agrupamiento. Los maestros pueden ser más eficientes en algunas clases que en otras clases, los estudiantes pueden estar agrupados por habilidad (por ejemplo, clases de educación especial), o algunas escuelas pueden tener mejor acceso a las computadoras que otras. Según Cameron y Miller, esta agrupación conducirá a:
- Errores estándar que son más pequeños que los errores estándar regulares de OLS .
- Intervalos de confianza estrechos .
- Estadísticas T que son demasiado grandes.
- Valores p engañosamente pequeños .
Los errores estándar incorrectos violan el supuesto de independencia requerido por muchos métodos de estimación y pruebas estadísticas y pueden conducir a errores de Tipo I y Tipo II .
Ajuste de errores estándar agrupados
Los errores estándar precisos son un componente fundamental de la inferencia estadística. Por lo tanto, si tiene CSE en sus datos (que a su vez producen SE inexactos), debe hacer ajustes para la agrupación antes de ejecutar más análisis de los datos.
Los cálculos manuales para errores estándar agrupados son algo complicados (en comparación con su fórmula estadística promedio). Por ejemplo, este fragmento de The American Economic Review brinda la fórmula de varianza para el cálculo de los errores estándar agrupados: por lo general, no es necesario realizar estos ajustes a mano, ya que la mayoría de los paquetes de software estadístico como Stata y SPSS tienen opciones para agrupar. Cuando especifica la agrupación en clústeres, el software se ajustará automáticamente para los CSE.
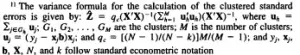
Una forma de controlar los errores estándar agrupados es especificar un modelo . Por ejemplo, podría especificar un modelo de coeficiente aleatorio o un modelo jerárquico . Sin embargo, la precisión de cualquier SE calculado depende completamente de que usted especifique el modelo correcto para la correlación de errores dentro del clúster. Una segunda opción es Cluster-Robust Inference , que no requiere que especifique un modelo. Sin embargo, tiene la suposición de que el número de grupos se aproxima al infinito (Ibragimov & Muller).
Referencias
Cameron y Miller. Guía práctica para la inferencia robusta en clústeres
Ibragimov, R. y Muller, U. Inferencia con pocos clústeres heterogéneos .
Primo, D. El investigador práctico. Estimación del impacto de las políticas e
instituciones estatales con datos de nivel mixto
Redactor del artículo
¿Te hemos ayudado?
Ayudanos ahora tú, dejanos un comentario de agradecimiento, nos ayuda a motivarnos y si te es viable puedes hacer una donación:La ayuda no cuesta nada
Por otro lado te rogamos que compartas nuestro sitio con tus amigos, compañeros de clase y colegas, la educación de calidad y gratuita debe ser difundida, recuerdalo:
