Contenido de este artículo
- 0
- 0
- 0
- 0
Actualizado el 25 de noviembre de 2021, por Luis Benites.
¿Qué es el agrupamiento aglomerativo?
El agrupamiento aglomerativo (también llamado ( agrupamiento aglomerativo jerárquico , o HAC)) es un tipo de agrupamiento jerárquico «de abajo hacia arriba». En este tipo de agrupación, cada punto de datos se define como un grupo. Los pares de clústeres se fusionan a medida que el algoritmo asciende en la jerarquía. La mayoría de los algoritmos de agrupamiento jerárquico son algoritmos de agrupamiento aglomerativo jerárquico.
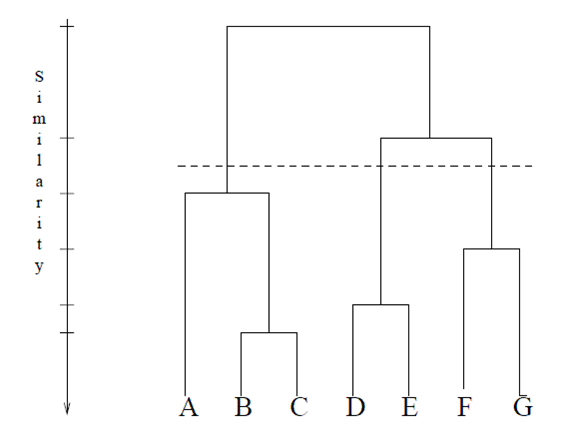
Métodos de agrupamiento aglomerativo
En el agrupamiento aglomerativo, cada documento se trata como un solo grupo al comienzo del algoritmo. Después de eso, los grupos se pueden combinar a través de una variedad de métodos. Todos implican el cálculo de diferencias entre objetos; Exactamente cómo se calcula esa diferencia puede variar. Los más utilizados son:
- Vinculación simple: la similitud se calcula para el par más cercano. Un inconveniente es que los grupos con pares cercanos pueden fusionarse antes de lo óptimo, incluso si esos grupos tienen diferencias generales.
- Enlace completo : calcula la similitud del par más lejano. Una desventaja de este método es que los valores atípicos pueden causar una fusión menos que óptima.
- Enlace promedio , o enlace de grupo: la similitud se calcula entre grupos de objetos, en lugar de objetos individuales.
- Método del centroide : cada iteración fusiona los grupos con el centroide más similar. Un centroide es el promedio de todos los puntos en el sistema.
- Método de Ward ( basado en ANOVA ): en cada paso, el proceso crea un nuevo grupo que minimiza la varianza , medida por un índice llamado E (también llamado índice de suma de cuadrados ).
Con todos los métodos, el proceso de emparejamiento continúa hasta que todos los elementos se fusionan en un solo grupo. A menudo, es posible que desee probar varios métodos y comparar los resultados para decidir cuál es la agrupación en clústeres más adecuada para su aplicación. No existe un método uniformemente mejor.
Desventajas
Una desventaja de los HAC es que tienen grandes requisitos de almacenamiento y pueden ser computacionalmente intensivos. Esto es especialmente cierto para los grandes datos. Estos algoritmos complejos tienen aproximadamente cuatro veces el tamaño del algoritmo K-means . Además, la fusión no se puede revertir, lo que puede crear un problema si tiene datos ruidosos y de gran dimensión.
Referencias
Aggarwal, C. (2013). Agrupación de datos: algoritmos y aplicaciones (Chapman & Hall/CRC Data Mining and Knowledge Discovery Series Book 31). Chapman & Hall/CRC.
Redactor del artículo
¿Te hemos ayudado?
Ayudanos ahora tú, dejanos un comentario de agradecimiento, nos ayuda a motivarnos y si te es viable puedes hacer una donación:La ayuda no cuesta nada
Por otro lado te rogamos que compartas nuestro sitio con tus amigos, compañeros de clase y colegas, la educación de calidad y gratuita debe ser difundida, recuerdalo:
