¿Qué es la agrupación?
La agrupación en estadísticas se refiere a cómo se recopilan los datos («agrupados») por factores como:
- Edad.
- Tamaño del hogar.
- Ingreso.
- O el nivel de educación.
La clasificación de datos en grupos a veces conduce a una mayor investigación de los datos. Por ejemplo, los grupos de cáncer pueden indicar algún problema en el medio ambiente. O bien, pueden ser simplemente el resultado de que la naturaleza sea aleatoria. El análisis de conglomerados tiende a ser subjetivo en muchos casos; depende de lo que perciba como hilos comunes en los datos. La técnica no es realmente nada nuevo en estadística; si alguna vez ha hecho un gráfico de barras , probablemente ya haya hecho grupos (incluso si no lo llamó así). Por ejemplo, un gráfico de barras que muestre razas de perros requiere que se agrupe por raza (husky siberiano, border collie, pastor alemán…) o un gráfico de niveles de ingresos podría agruparse por niveles de ingresos bajos, medios y altos.
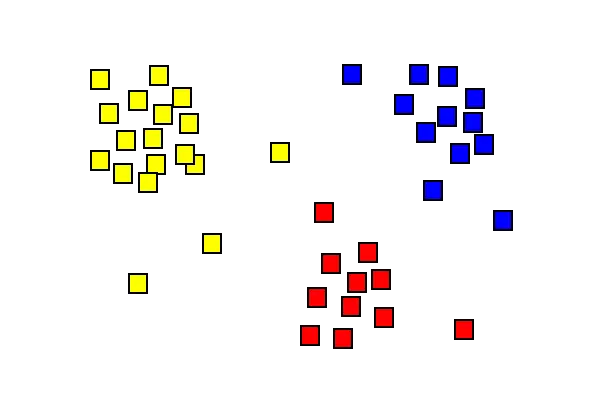
Resultados del análisis de conglomerados que muestran tres conglomerados de diferentes colores.
Los clústeres pueden basarse en factores como:
- Agrupamiento basado en la distancia . Los elementos se ordenan en función de su proximidad (o distancia). Por ejemplo, los casos de cáncer pueden agruparse si se encuentran en la misma ubicación geográfica.
- Agrupamiento conceptual. Los elementos se agrupan por factores que los elementos tienen en común. Por ejemplo, los grupos de cáncer podrían agruparse por «personas que trabajan en la fabricación».
Tipos de agrupamiento
- Agrupamiento exclusivo . Cada elemento solo puede pertenecer a un solo grupo. No puede pertenecer a otro clúster.
- Agrupamiento difuso : a los puntos de datos se les asigna una probabilidad de pertenecer a uno o más grupos.
- Agrupamiento superpuesto . Cada elemento puede pertenecer a más de un clúster.
- Agrupación jerárquica . Este es un enfoque más complejo para la agrupación en clústeres que se utiliza en la minería de datos. Básicamente, a cada elemento se le asigna su propio grupo. Se une un par de grupos en función de las similitudes, lo que da un grupo menos. Este proceso se repite hasta que se agrupan todos los elementos. El dendrograma es un gráfico que muestra grupos jerárquicos.
- Agrupación Probabilística . Los datos se agrupan mediante algoritmos que conectan elementos mediante distancias o densidades. Esto generalmente lo realiza una computadora.
- Método de Ward: utiliza la varianza mínima en cada paso para crear grupos relativamente pequeños de tamaño uniforme.
K significa agrupamiento
La agrupación en clústeres es solo una forma de agrupar un conjunto de datos en conjuntos más pequeños. Las dos formas de agrupar un conjunto de datos son cuantitativamente (usando números) y cualitativamente (usando categorías). Por ejemplo, los libros en Amazon.com se enumeran tanto por categoría (cualitativo) como por best seller (cuantitativo). La agrupación en clústeres de K-Means es uno de los algoritmos de aprendizaje no supervisados más simples que resuelve problemas de agrupación mediante un método cuantitativo: usted predefine una cantidad de clústeres y emplea un algoritmo simple para clasificar sus datos. Dicho esto, «simple» en el mundo de la computación no equivale a simple en la vida real. Esto es en realidad un NP-duro problema, por lo que querrá usar software para la agrupación en clústeres de K-means. Algunos programas que realizarán esto por usted (haga clic en el enlace para el procedimiento) son:
Los pasos generales detrás del algoritmo de agrupamiento de K-means son:
- Decide cuántos conglomerados (k).
- Coloque k puntos centrales en diferentes lugares (generalmente alejados entre sí).
- Tome cada punto de datos y colóquelo cerca del punto central apropiado. Repita hasta que se hayan asignado todos los puntos de datos.
- Vuelva a calcular k nuevos puntos centrales como baricentros .
- Repita la asignación de puntos de datos, esta vez al nuevo punto central (el baricentro).
- Repita 4 y 5 hasta que los puntos centrales (baricentros) no se muevan más.
Agrupamiento de K-Means: una definición más formal
Una forma más formal de definir el agrupamiento de K-Means es categorizar n objetos en k(k>1) grupos predefinidos. El objetivo es minimizar la distancia desde cada punto de datos hasta el clúster. En otras palabras, para encontrar: donde: X es un punto de datos k es el número de conglomerados u i es la media de los puntos en S i.
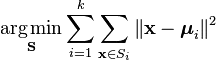
Análisis de conglomerados frente a análisis discriminante
El análisis de conglomerados es muy similar al análisis discriminante. Ambos métodos implican la separación en grupos. Sin embargo, el análisis de conglomerados es una forma de identificar los grupos, mientras que el análisis discriminante requiere que conozca los grupos antes de comenzar el análisis. Por ejemplo, supongamos que tiene un grupo de pacientes psiquiátricos con comportamientos anormales. El análisis de conglomerados podría ayudarlo a encontrar grupos distintos, como pacientes con antecedentes de abuso, aquellos con PTSD o aquellos que experimentan alucinaciones. Si tuviera que ejecutar un análisis discriminante en el mismo grupo de personas, debe conocer los diagnósticos de los pacientes antes de comenzar a clasificarlos en grupos.
Agrupación en Excel
Microsoft Excel tiene un complemento de minería de datos para crear clústeres. Puede encontrar instrucciones aquí . El asistente funciona con tablas de Excel, rangos o consultas de encuestas de análisis. Este complemento se puede personalizar, a diferencia de la herramienta Detectar categorías . Además, la herramienta Detectar categorías se limita a datos de tablas.
Usar:
- Descargue e instale el complemento de minería de datos .
- Haga clic en «Minería de datos», luego haga clic en «Cluster» y luego en «Siguiente».
- Dile a Excel dónde están tus datos. Por ejemplo, seleccione un rango de datos. La página de agrupación estará disponible.
- Agrupación: déjelo como está para la agrupación automática, o puede especificar una cantidad de grupos.
- Segmentos: déjelo como está para la agrupación automática o especifique una serie de categorías.
- Anule la selección de las columnas que no sean entradas útiles para su análisis. Por ejemplo, es posible que desee anular la selección de números de identificación, fechas de nacimiento u otros identificadores.
- Dígale a Excel cuántos datos esperar para la prueba (en la página Dividir datos en entrenamiento y prueba). El valor predeterminado es 30 % de prueba/70 % de capacitación.
- Dale un nombre a tu modelo. Marque la opción «Examinar» para ver inmediatamente sus resultados.