Contenido de este artículo
- 0
- 0
- 0
- 0
Actualizado el 20 de abril de 2022, por Luis Benites.
¿Qué es el análisis semántico latente?
El análisis semántico latente (LSA) es una forma de analizar cómo se usan las palabras y los grupos de palabras en los textos. Se utiliza para responder preguntas como:
- ¿Cuál es el significado subyacente del texto?
- ¿Qué efecto tienen las palabras en el significado de los pasajes?
- ¿Cómo se relaciona el significado promedio de las palabras en un pasaje con el significado general de un pasaje?
El lenguaje (especialmente el inglés) es complejo, en parte porque las palabras tienen múltiples significados. Por ejemplo, la palabra «caliente» puede significar una variedad de cosas que incluyen «casi hirviendo», «sexy» o «precio de venta». Mucho depende del contexto en el que lo esté usando (es decir, el pasaje que lo rodea). “Caliente” en un texto puede tener un significado completamente diferente en otro, por lo que encontrar palabras, pasajes o textos completos relacionados no es tarea fácil. LSA intenta hacer esto asignando palabras a conceptos como «temperatura», «sexo» o «negocio». Luego se comparan las palabras y los conceptos vinculados para llegar al significado real del texto.
El análisis semántico latente también se denomina indexación semántica latente (LSI) .
Método
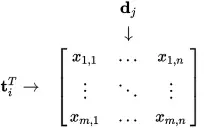
Una matriz donde cada elemento muestra con qué frecuencia aparecen las palabras en un texto.
LSA utiliza un método avanzado de álgebra matricial llamado Descomposición de valores singulares (SVD) para factorizar matrices . Por lo general, SVD no es práctico de realizar a mano para algo más que una pequeña muestra de texto. De hecho, solo se hizo popular después de la década de 1980, cuando las computadoras aparecieron en escena para manejar los complejos algoritmos.
El método básico es:
- El texto se convierte en matrices para representar pasajes. Cada celda de la matriz contiene el número de veces que aparece una determinada palabra en un determinado pasaje.
- La matriz se factoriza para que cada pasaje se represente como un vector . El valor de cada vector es la suma de los vectores que representan sus palabras componentes.
- Los productos de puntos, cosenos o métricas similares se utilizan para representar similitudes entre palabras y pasajes.
La teoría detrás de los algoritmos utilizados en SVD está más allá del alcance de este artículo, pero puede leer más al respecto en este artículo de la Universidad de Victoria .
Referencias
Thomo, A. Análisis Semántico Latente (Tutorial). Recuperado el 28 de mayo de 2020 de: https://www.engr.uvic.ca/~seng474/svd.pdf
Redactor del artículo
¿Te hemos ayudado?
Ayudanos ahora tú, dejanos un comentario de agradecimiento, nos ayuda a motivarnos y si te es viable puedes hacer una donación:La ayuda no cuesta nada
Por otro lado te rogamos que compartas nuestro sitio con tus amigos, compañeros de clase y colegas, la educación de calidad y gratuita debe ser difundida, recuerdalo:
