¿Qué es un puntaje de propensión?
Un puntaje de propensión es la probabilidad de que una unidad con ciertas características sea asignada al grupo de tratamiento (a diferencia del grupo de control ). Los puntajes se pueden usar para reducir o eliminar el sesgo de selección en estudios observacionales al equilibrar las covariables (las características de los participantes) entre los grupos tratados y de control. Cuando las covariables están equilibradas, se vuelve mucho más fácil emparejar participantes con múltiples características.
¿Qué es la coincidencia de puntuación de propensión?
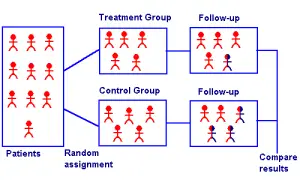
La coincidencia de puntuación de propensión se aproxima a un ensayo aleatorio para emparejar controles con sujetos experimentales. Imagen: SUNY Downstate.
La coincidencia de puntuación de propensión crea conjuntos de participantes para los grupos de tratamiento y control. Un conjunto emparejado consta de al menos un participante en el grupo de tratamiento y uno en el grupo de control con puntajes de propensión similares. El objetivo es aproximar un experimento aleatorio, eliminando muchos de los problemas que surgen con el análisis de datos de observación.
Los diseños coincidentes pueden ser bipartitos o no bipartitos . El pareamiento bipartito es equivalente al muestreo sin reemplazo , mientras que los diseños de pareamiento no bipartito son equivalentes al muestreo con reemplazo . Los diseños bipartitos son más comunes, pero los diseños no bipartitos están disponibles para el caso poco frecuente de querer reutilizar un miembro; Por ejemplo, si usa el mismo control como coincidencia para dos o más participantes del grupo de tratamiento.
El emparejamiento no es la única forma en que se pueden usar los puntajes de propensión para controlar la confusión . Otros métodos populares incluyen la estratificación , el ajuste de regresión y la ponderación .
Pasos básicos
Los pasos básicos para la coincidencia de puntuación de propensión son:
- Recolectar y preparar los datos.
- Estime los puntajes de propensión. Se desconocen las puntuaciones reales, pero se pueden estimar mediante muchos métodos, incluidos: análisis discriminante, regresión logística y bosques aleatorios. El «mejor» método está sujeto a debate, pero uno de los métodos más populares es la regresión logística.
- Empareje a los participantes usando los puntajes estimados.
- Evalúe las covariables para una distribución uniforme entre los grupos. Las puntuaciones son buenas estimaciones de las puntuaciones de propensión verdaderas si el proceso de emparejamiento distribuye con éxito las covariables entre los grupos tratados/no tratados (Ho et. al, 2007).
Algoritmos de coincidencia
Los métodos de coincidencia para diseños de coincidencia bipartitos constan de dos partes: una relación de coincidencia y un algoritmo de coincidencia. La relación de emparejamiento puede ser uno a uno (uno del tratamiento a uno del control), variable (la computadora decide la relación óptima) o fija (cada control se empareja con k miembros del grupo de tratamiento). El algoritmo de coincidencia es donde realmente tiene lugar la coincidencia.
Uno de los algoritmos más populares es la coincidencia codiciosa , que incluye la coincidencia de calibre (se especifica una distancia máxima permitida entre los puntajes de propensión) y la coincidencia del vecino más cercano (empareja a cada participante del grupo de tratamiento con el participante del grupo no tratado más cercano posible).
Otros algoritmos comunes incluyen:
- Coincidencia genética : verifica iterativamente los puntajes de propensión y los mejora usando una combinación de coincidencia de puntaje de propensión y coincidencia de distancia de Mahalanobis (Diamond & Sekhon, 2012).
- Emparejamiento óptimo: se minimiza la distancia entre los participantes tratados y no tratados. El algoritmo tiene en cuenta todo el sistema antes de realizar cualquier coincidencia (Rosenbaum, 2002).
Para los diseños no bipartitos, el procedimiento de correspondencia se vuelve mucho más complicado. El algoritmo habitual es el arranque , que consiste en dibujar muestras de arranque .
El paso del algoritmo de coincidencia generalmente se realiza con software .
- Tanto R ( MatchIt ) como SAS tienen procedimientos para una coincidencia bipartita óptima.
- Las opciones de coincidencia no bipartita son extremadamente limitadas, pero incluyen el paquete nbpMatching para R.
- La función psmatch en STATA puede manejar coincidencias bipartitas y no bipartitas; Está orientado a aplicaciones económicas.
Crítica
El verdadero puntaje de propensión nunca se conoce en los estudios observacionales, por lo que nunca puede estar seguro de que las estimaciones del puntaje de propensión sean precisas. Algunos autores piden precaución al conocer las limitaciones de lo que realmente equivale a una herramienta de estimación, y tratar de aproximar un experimento aleatorio a partir de datos de observación puede estar plagado de trampas. Otros (p. ej., King, 2016) piensan que estas puntuaciones no deberían usarse para emparejar en absoluto.
Para evitar trampas, Rosenbaum y Rubin recomiendan verificar iterativamente el puntaje de propensión para el equilibrio; Proporcionan detalles sobre el procedimiento en su artículo de 1983. Esto suena simple, pero en la práctica puede ser muy desafiante. La coincidencia genética de Diamond y Sekhon es un método alternativo para lograr el equilibrio, lo que elimina la necesidad de verificaciones iterativas.
Referencias:
Diamond, A. & Sekhon, J. (2013). Emparejamiento genético para estimar los efectos causales: un método general de emparejamiento multivariante para lograr el equilibrio en los estudios observacionales. La Revista de Economía y Estadística. julio de 2013, vol. 95, No. 3, Páginas: 932-945.
Ho et. al (2007). Emparejamiento como preprocesamiento no paramétrico para reducir la dependencia del modelo en la inferencia causal paramétrica. Análisis Político, 15(3).
King, G. & Nielsen, R. Por qué prop. las puntuaciones no deben utilizarse para el emparejamiento. Recuperado el 2 de febrero de 2017 de: http://gking.harvard.edu/files/gking/files/psnot.pdf
Rosenbaum, P. y Rubin, D. (1983). El papel central de la utilería. puntuación en estudios observacionales para efectos causales. Biométrica . 1 de abril.
ROSENBAUM, PR (2002). Estudios observacionales, 2ª ed. Springer, Nueva York. MR1899138
Imagen: SUNY Downstate. Recuperado el 8 de agosto de 2019 de: http://library.downstate.edu/EBM2/2200.htm