Contenido de este artículo
- 0
- 0
- 0
- 0
Actualizado el 23 de marzo de 2022, por Luis Benites.
¿Qué es un algoritmo codicioso?
El algoritmo codicioso es uno de los algoritmos más simples de implementar: toma la opción más cercana/más cercana/más óptima y repite. Siempre elige qué elemento de un conjunto parece ser el mejor en ese momento. Nunca cambia de opinión en un momento posterior.
Los algoritmos codiciosos son «de arriba hacia abajo», lo que significa que el algoritmo hace una elección codiciosa y luego otra, reduciendo los problemas grandes a los más pequeños. La idea es que al elegir el elemento más sabroso (más óptimo) en cualquier momento, el sistema general finalmente se optimizará. La mayoría de los problemas no se pueden optimizar con un algoritmo codicioso, pero funciona en algunos casos (como la coincidencia codiciosa).
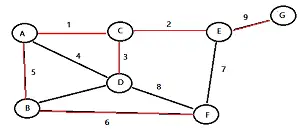
Un árbol de expansión mínima (mostrado en rojo) minimiza los bordes (pesos) de un árbol.
Para ver un ejemplo de cómo funciona un algoritmo codicioso simple, consulte: Algoritmo de Boruvka (Algoritmo de Sollin) , que es una forma de encontrar un árbol de expansión mínimo donde se minimiza la suma de los pesos de los bordes.
Algoritmo de coincidencia codicioso
El objetivo de un algoritmo de emparejamiento codicioso es producir muestras emparejadas con covariables equilibradas (características) en todo el grupo de tratamiento y el grupo de control. Puede generar pares coincidentes de uno a uno o de uno a muchos muestreados sin reemplazo . El muestreo sin reemplazo significa que una vez que se ha emparejado a una persona, no se la puede utilizar en otra coincidencia.
El vecino más cercano codicioso es una versión del algoritmo que funciona eligiendo un miembro del grupo de tratamiento y luego eligiendo un miembro del grupo de control que sea la coincidencia más cercana. Por ejemplo:
- Elija al participante con el puntaje de propensión más alto (un puntaje de propensión es la probabilidad de ser asignado al grupo de tratamiento).
- Seleccione un miembro del grupo de control con el puntaje de propensión más cercano a la persona elegida en el Paso 1.
- Elija un segundo miembro del grupo de tratamiento (en este ejemplo, con el siguiente rango de puntaje de propensión más alto), haga coincidir al segundo participante.
- Repita el proceso hasta que todos los participantes coincidan.
No tiene que comenzar con el participante con el puntaje de propensión de rango más alto. Otras opciones son:
- Puntuación de menor a mayor .
- Mejor partido posible : se elige un par con las puntuaciones más cercanas. Se eliminan del conjunto, luego se elige otro par con las siguientes puntuaciones más cercanas, y así sucesivamente.
- Selección aleatoria : los pares se eligen al azar utilizando una semilla aleatoria.
- Coincidencia de calibre: se establece una distancia máxima de calibre para las coincidencias. Una distancia de calibre es la diferencia absoluta en los puntajes de propensión para los partidos. Dado que se establece un valor máximo, es posible que algunos participantes no coincidan.
Desventajas
La coincidencia codiciosa del vecino más cercano puede resultar en coincidencias de mala calidad en general. Los primeros partidos pueden ser buenos partidos y el resto malos partidos. Esto se debe a que se optimiza una coincidencia a la vez, en lugar de todo el sistema. Una alternativa es el emparejamiento óptimo, que tiene en cuenta todo el sistema antes de realizar cualquier emparejamiento (Rosenbaum, 2002). Cuando hay mucha competencia por los controles, la coincidencia codiciosa funciona mal y la coincidencia óptima funciona bien. El método que utilice puede depender de su objetivo; el emparejamiento codicioso creará grupos bien emparejados, mientras que el emparejamiento óptimo creará parejas bien emparejadas (Stuart, 2010).
Programas de emparejamiento codiciosos
- En R: Ejecute MatchIt . La coincidencia predeterminada de vecinos más cercanos es la coincidencia codiciosa.
- En SAS: varias macros están disponibles para la coincidencia uno a uno, incluida la macro de Parson y el gmatch de Kosanke & Bergstral .
Referencias :
Austin, P. (2014). Una comparación de 12 algoritmos para hacer coincidir el puntaje de propensión. Recuperado el 3 de febrero de 2017 de: Stat Med. 15 de marzo de 2014; 33(6): 1057–1069.
ROSENBAUM, PR (2002). Estudios observacionales, 2ª ed. Springer, Nueva York. MR1899138
Estuardo, E. (2010). Métodos de emparejamiento para la inferencia causal: una revisión y una mirada hacia el futuro. ciencia estadística 2010 1 de febrero; 25(1): 1–21.
Redactor del artículo
¿Te hemos ayudado?
Ayudanos ahora tú, dejanos un comentario de agradecimiento, nos ayuda a motivarnos y si te es viable puedes hacer una donación:La ayuda no cuesta nada
Por otro lado te rogamos que compartas nuestro sitio con tus amigos, compañeros de clase y colegas, la educación de calidad y gratuita debe ser difundida, recuerdalo:
