Actualizado por ultima vez el 17 de noviembre de 2021, por Luis Benites.
Los datos influyentes consisten en puntos de datos que influyen (sesgan) un análisis de manera importante. Son valores atípicos que tienen suficiente influencia para cambiar significativamente una línea de regresión o coeficientes estadísticos ; eliminarlos lleva un análisis a una conclusión diferente.
Propiedades de los datos influyentes
Un punto de datos influyente tiene dos propiedades clave:
- Tiene propiedades que no son representativas de los otros puntos de datos . No sigue la tendencia general y el valor de la variable dependiente es inesperado dado los valores que obtendría de las variables predictoras .
- Tiene apalancamiento : la capacidad de mover una línea de regresión hacia sí misma.
La identificación de datos influyentes es importante porque el análisis de regresión no es resistente a los valores atípicos influyentes; una medición incorrecta tiene el potencial de desbaratar por completo un análisis. Dado que todo el muestreo de datos es propenso al error humano, es importante estar abierto a la posibilidad de que no todos nuestros puntos de datos sean completamente válidos.
Dos fórmulas pueden ayudar a identificar puntos de datos influyentes en un conjunto de datos: Cook’s D y DFFits.
D de cocinero
Esta fórmula viene dada por:
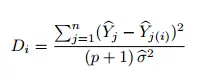
Cook’s D tiene más de una interpretación, por lo que puede ser complicado de usar. Para obtener más detalles, consulte: ¿Qué es la D de Cook?
Fórmula de distancia de ajuste (DFFits)
DFFits se escribe como:
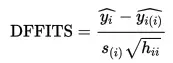
s i es una estimación del error estándar de la pendiente de regresión , h ii es el apalancamiento del punto, y ŷ i y ŷ i(i) son predicciones de respuesta con y sin el punto incluido en la regresión.
La primera parte de la fórmula representa las respuestas de datos previstas sin que se analice el punto, y el segundo término representa con. Básicamente, está descubriendo cuánta diferencia hace ese punto. El denominador en realidad representa la desviación estándar estimada del cambio en las respuestas previstas.
Eso significa que el número que nos da la fórmula DFFITS es el número de desviaciones estándar que cambia su variable de respuesta cuando se admite su punto de interés.
Si DFFITS para un punto de datos es mayor que
![]()
ese punto se puede clasificar como datos influyentes.
Se puede utilizar cualquiera de los métodos anteriores para marcar datos influyentes; en general, se recomienda ir con lo que sea más fácil de ejecutar en el paquete de software que está utilizando para el análisis de datos.
Referencias
O’Halloran, S. (nd). Comprobación de modelos. Recuperado el 30 de diciembre de 2017 de http://www.columbia.edu/~so33/SusDev/Lecture_5.pdf
Penn State (2017). Métodos de regresión: Identificación de puntos de datos influyentes
Obtenido el 31 de diciembre de 2017 de https://onlinecourses.science.psu.edu/stat501/node/340
Sampson, P. (2010). Stat 423: Datos inusuales e influyentes
Obtenido el 30 de diciembre de 2017 de http://www.stat.washington.edu/pds/stat423/Documents/LectureNotes/notes.423.ch11.pdf.

